一、 目的
为了在软件生命周期内规范数据库相关的设计、开发、运维工作,便于不同团队之间的沟通及协调,制定此文档,以期在相关规范上达成共识和默契,提升相关环节的工作效率及系统的可维护性。同时好的规范,在执行的时候可以培养出好的习惯,好的习惯是软件质量的很好保证。
二、 使用范围
本文档适用于研发人员、运维开发成员、DBA等所有能接触数到据库的人员。
三、分布式数据库TiDB
3.1 使用限制
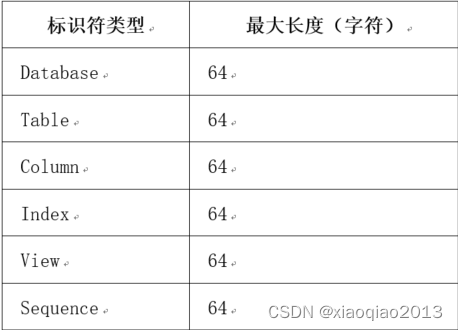
3.1.1、标识符长度限制
3.1.2、事务限制
TiDB 单个事务大小限制:数据批处理时,默认100MB,最大不超过10GB;
单行数据的大小限制:默认6MB,最大不超过120MB(开发时注意Json,文本存储等卡类型)
单个事务包含的 SQL 语句不超过 5000 条(默认)
3.1.3、与MySQL兼容性限制
存储过程与函数
触发器
事件
自定义函数
外键约束
非 ascii/latin1/binary/utf8/utf8mb4 的字符集
XML 函数
列级权限 #9766
CREATE TABLE tblName AS SELECT tb_1

3.1.4、AUTO_INCREMENT限制
必须定义在主键或者唯一索引的列上
只能定义在类型为整数、FLOAT 或 DOUBLE 的列上
不支持与列的默认值 DEFAULT 同时指定在同一列上
不支持使用 ALTER TABLE 来添加 AUTO_INCREMENT 属性
支持使用 ALTER TABLE 来移除 AUTO_INCREMENT 属性
在集群中有多个 TiDB 实例时,如果表结构中有自增 ID,建议不要混用显式插入和隐式分配(即自增列的缺省值和自定义值),否则可能会破坏隐式分配值的唯一性
如:客户端A插入id=2(id 为自增),客户端B插入id=1;客户端A再次插入时会返回 Duplicated Error 错误。(多台TiDB机器插入不保证连续)
解决:
确认表上自增值的最大值:show create table tb_1;
修改表上的自增值最大值到一个更大的值:alter table tb_1 AUTO_INCREMENT=120000;
TiDB 的自增列仅保证唯一,也能保证在单个 TiDB server 中自增,但不保证多个 TiDB server 中自增,不保证自动分配的值的连续性
3.1.5、DDL限制
不能在单条 ALTER TABLE 语句中完成多个操作。例如,不能在单个语句中添加多个列或索引,否则,可能会输出 Unsupported multi schema change 的错误。

3.2 开发规范
3.2.1、字符集
TiDB 默认:utf8mb4。
MySQL 5.7 默认:utf8mb4。(MySQL默认latin1,标准安装默认utf8mb4)
MySQL 8.0 默认:utf8mb4。
3.2.2、排序规则
TiDB 中 utf8mb4 字符集默认:utf8mb4_bin。
MySQL 5.7 中 utf8mb4 字符集默认:utf8mb4_general_ci。
MySQL 8.0 中 utf8mb4 字符集默认:utf8mb4_0900_ai_ci。
3.2.3、SQL Mode
TiDB 默认:
ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION。
MySQL 5.7 默认与 TiDB 相同。
MySQL 8.0 默认
ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION。
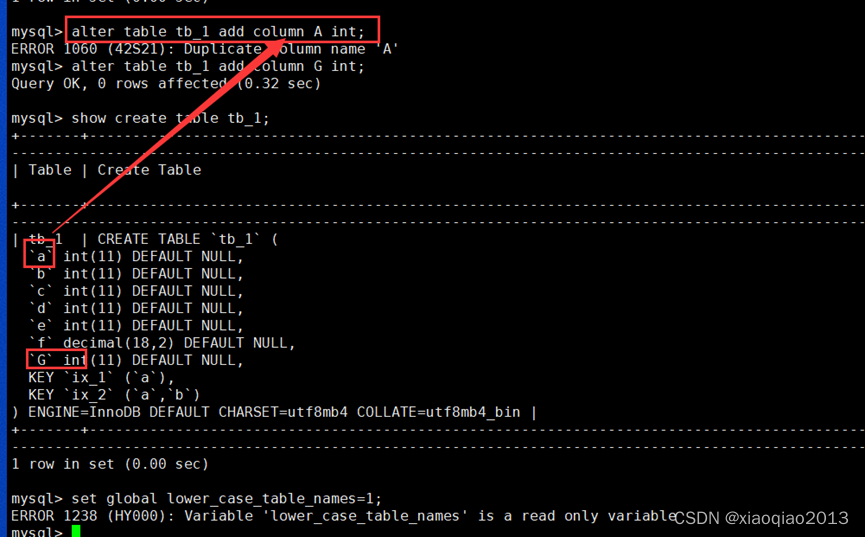
3.2.4、lower_case_table_names
TiDB 默认:2,且仅支持设置该值为 2。
lower_case_table_names = 1 表名存储在磁盘是小写的,但是比较的时候是不区分大小写
lower_case_table_names=0 表名存储为给定的大小和比较是区分大小写的
lower_case_table_names=2, 表名存储为给定的大小写但是比较的时候是小写的
3.2.5、删除数据
【建议】删除表中全部的数据时,使用 TRUNCATE 或者 DROP 后重建方式,不要使用 DELETE;
原因:DELETE,TRUNCATE 和 DROP 都不会立即释放空间,对于 TRUNCATE 和 DROP 操作,在达到 TiDB 的 GC (garbage collection) 时间后(默认 10 分钟),TiDB 的 GC 机制会删除数据并释放空间。对于 DELETE 操作 TiDB 的 GC 机制会删除数据,但不会释放空间,而是当后续数据写入 RocksDB 且进行 compact 时对空间重新利用。
3.2.6、GROUP_CONCAT
由于 group_concat() 中没有使用 order by 导致结果集不稳定;
结果集不稳定是因为 TiDB 是并行地从存储层读取数据,所以 group_concat() 不加 order by 的情况下得到的结果集展现顺序容易被感知到不稳定。
mysql> select group_concat(name order by name) from tb_2;
3.2.7、其他
【建议】WHERE条件中不在索引列上进行数学运算或函数运算;
【建议】用 in/union 替换 or,并注意 in 的个数小于 300;
【建议】禁止使用%前缀进行模糊前缀查询;
【建议】如应用使用 Multi Statements 执行 SQL,即将多个 SQL 使用分号连接一次性发给客户端执行,TiDB 只会返回第一个 SQL 的执行结果。
3.3 命名规范
3.3.1、大原则
【要求】命名建议使用具有意义的英文词汇,词汇中间以下划线分隔;避免中划线;
【要求】命名只能使用英文字母、数字、下划线;
【要求】避免用 TiDB 的保留字如:group,order 等作为单个字段名;
【要求】所有数据库对象使用小写字母;
【要求】避免特殊字符。
【建议】参考MySQL命名规范,保持一致
3.3.2、数据库命名规范
建议按照业务、产品线或者其它指标进行区分,一般不要超过 20 个字符。如:临时库(tmp_cbb)、测试库(test_cbb)。
3.3.2、表命名规范
参考MySQL命名规范
【建议】同一业务或者模块的表尽可能使用相同的前缀,表名称尽可能表达含义;
【建议】多个单词以下划线分隔,不推荐超过32个字符;
【建议】建议对表的用途进行注释说明,以便于统一认识。
如:临时表(tmp_t_crm_relation_0425)
备份表(bak_t_crm_relation_20170425)
业务运营临时统计表(tmp_st_[业务代码][创建人缩写][日期])
账期归档表(t_crm_ec_record_YYYY[MM][DD])
【建议】不同业务模块的表单独建立 DATABASE,并增加相应注释。
3.3.3、字段命名规范
【建议】字段命名需要表示其实际含义的英文单词或简写;
【建议】建议各表之间相同意义的字段应同名;
【要求】字段需要添加注释,枚举型需指明主要值的含义,如”0 - 离线,1 - 在线”;
【要求】布尔值列命名为 [is_描述]。如 member 表上表示