简介
简要的介绍下TiKV的架构。

底层存储RocksDB

RocksDB的写操作

在写入WAL的时候为了防止操作系统写入的时候有缓存,要设置操作系统的参数sync_log=true,也就是说只要有数据就执行刷写到磁盘,就不会存储到操作系统的缓存了。MemTable的数据到达一定的大小以后,就会刷写到immutable里面。

level 0的数据就是 immutable是什么数据就会存储什么数据。
如果level 0到达4个以后,就会启动内部的compation操作(数据压缩加数据排序的操作),(每一层的level数据都是排好顺序的),查找的时候是根据二分查找的方法进行对应的数据查找,写的时候都是顺序写,包括它的删除操作也是一条写记录,但是查找的时候,就会过滤掉有删除标志的数据。
RocksDB的读操作

Block Cache是读取数据的缓存。每一个level里面的SST文件都记录了一个最大值和最小值,查找数据的时候,先比对最大值和最小值,如果在这个范围内,那么就会使用二分查找的方法进行数据查找。
RocksDB的Colume Families

这里也就是说他们的key-value一类的数据放在不同的Colume Family中,如果不执行Colume Family那么默认就会到default的Colume Family中,这个就是RocksDB的分片技术。
分布式事务
分布式事务前提

1.先从PD得到一个开始的时间。
2.如果在用户commit的时候锁的信息才写入到TiKV中,那么这个就是乐观锁(这里之前修改的数据是在内存,只有用户commit的时候才会写入锁的信息)在用户commit的时候就会执行prewrite步骤。
3.如果想修改的操作提前让其他的用户知道,那么在用户修改的时候就已经把锁的信息写入到 TiKV中。
4.在写任何操作的时候,都会在default的后面直接添加数据,包括增删改查。
5.write里面的Colume Family信息是最近的一次数据完成的事务操作的记录信息。write记录以后,然后在Lock的Colume Family添加一条删除锁的记录。
6.用户读取信息的时候会先在write中查找最新的完成操作的记录,然后再到default中查找数据。
注意事项

TiDB解决分布式事务的原理

1.prewrite操作会写入对应节点的default里面,并且会写入Lock数据(分布式事务的第一行加主锁,其他的条数加从锁,也就是存储了主锁的指向)。
2.在主锁节点的事务完成以后,如果从锁的数据节点发生了宕机,那么数据节点重启以后,会找到主锁对应的节点是否事务完成了,如果完成了,那么他会更具主锁上面的事务是否完成来修复自己节点的数据。

MVCC(解决事务上锁读数据的问题)
也就是说自己事务读取的数据是自己执行时间之前的数据,多版本并发控制来管理每一个客户端,不同时间看到不同的数据。

Raft和Muti Raft(分布式数据一致性)

日志复制


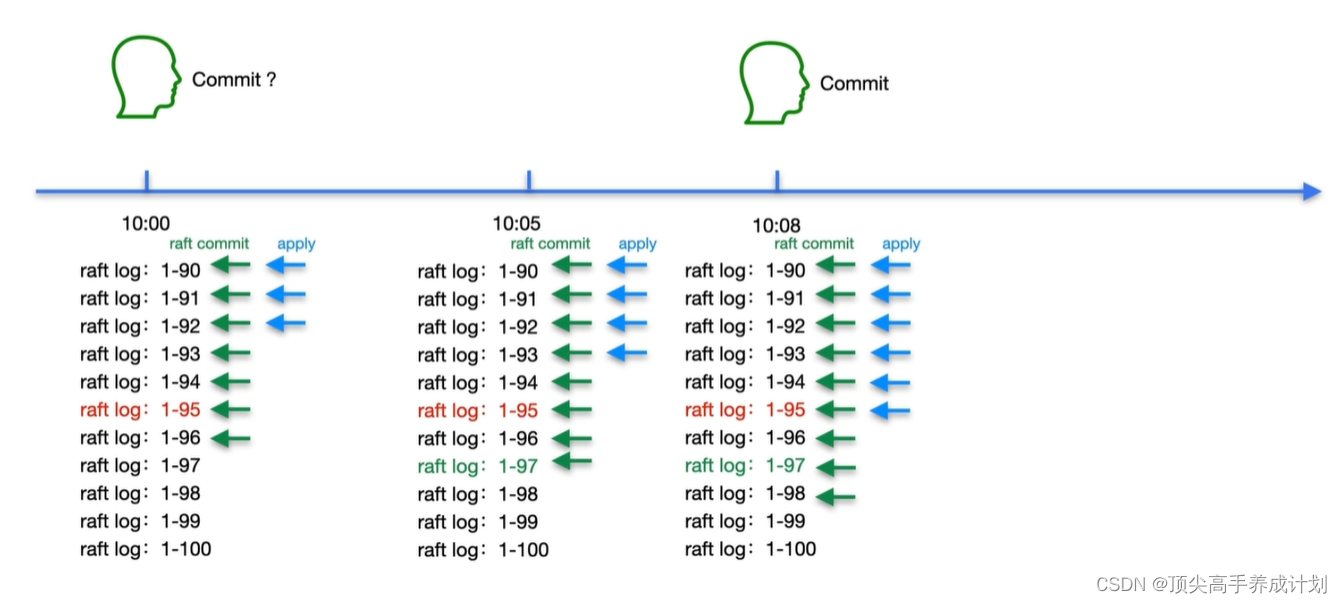
raft的commit以后并不代表用户的commited已经成功了。

当数据真正写入到rocksdb kv以后,那么表示用户的commited完成了。

Raft Leader选举

选举相关超时参数

TiKV写入
数据写入

TiDB Server的写请求会发送给raftstore pool。
raftstore pool会把写请求,装换成raft log。
使用raft协议同步数据。
然后执行raft 的commit ,apply pool将raft log写入到rocksdb kv中,那么用户的commit 就完成了。
数据读取
数据读取的时候要找到region的leader位置。

ReadIndex Read
读取数据的时间线图
 数据只有apply以后才能够查看到。
数据只有apply以后才能够查看到。
Lease Read
由于读取数据的时候要找到对应的leader才行,那么要想优化。

在指定的心跳时间内,那么在重新选举的时候,那么它都是leader。
Follower Read
上面的两种都只能读取leader的数据,这种就可以读取Follower的数据。

在leader的修改
在follower

在所有的修改比如1-97的修改,它们一定都会在 1-97之前。
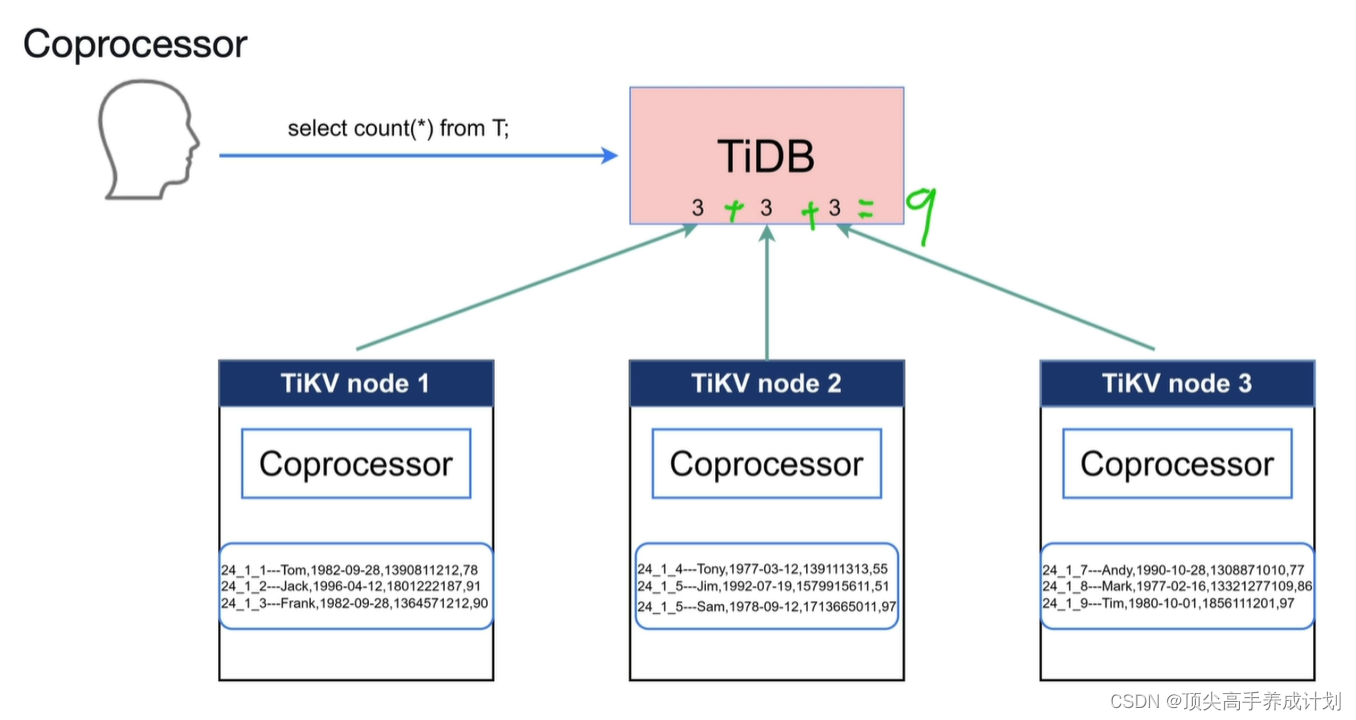
Coprecessor

如果不使用Coprecessor,那么很多的聚合操作都会给TiDB

有了Coprecessor,那么计算就会下推到TiKV节点(算子下推)。