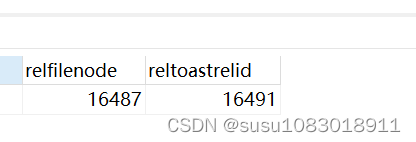
编写这个笔记,希望能记录下学习TiDB时候的知识点。
目录
参考文章
第五章
1.数据库和字符集
参考文章
| 目的 | 链接&详细 |
|---|---|
| TiDB Books | TiDB 6.x in Action | TiDB Books 【6.0版】 Introduction · TiDB in Action 【4.0版】 |
| TiDB-学习笔记_tidb 查询_R&Y的博客-CSDN博客 |
第五章
对应课程
TiDB 特有功能与事务控制 [TiDB v6.1](201.3)的“02 数据库与字符集”
1.数据库和字符集
数据库名建议按照业务、产品线或者其它指标进行区分,一般不要超过 20 个字符。
*数据库里的对象命名只能使用英文字母、数字和下划线
*名称不能超过 64 个字符
*不能使用某些字符,包括 ASCII(0), ASCII(255), /, \, .
*可以使用保留字和特殊字符,但前提是使用 反引号` 将其包围
CREATE DATABASE 用于创建数据库,并可以指定数据库的默认属性(如数据库默认字符集、排序规则)。
CREATE SCHEMA 和 CREATE DATABASE 操作效果一样。
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name
[create_specification] ...
create_specification:
[DEFAULT] CHARACTER SET [=] charset_name
| [DEFAULT] COLLATE [=] collation_name
当创建已存在的数据库且不指定使用 IF NOT EXISTS 时会报错。
create_specification 选项用于指定数据库具体的 CHARACTER SET 和 COLLATE。目前 TiDB 只支持将 lower-case-table-names 值设为 2,即按照大小写来保存表名,按照小写来比较(不区分大小写)。
创建 Schema/Database
语法:
CREATE DATABSAE [IF NOT EXISTS] database_name [options];
CREATE SCHEMA [IF NOT EXISTS] schema_name [options];
删除数据库:DROP DATABASE [IF EXISTS] database_name;
小心这是一个无法撤消的操作
TiDB 以区分大小写的方式存储对象名,但以不区分大小写的方式进行比较
tidb> show variables like 'lower_case_%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| lower_case_file_system | 1 |
| lower_case_table_names | 2 |
+------------------------+-------+目前 TiDB 只支持部分的字符集和排序规则,会在后续的内容中讲解。
字符集和排序规则
SHOW CHARACTER SET: 列出支持的字符集
SHOW COLLATION: 列出支持的排序规则
tidb> SHOW COLLATION;
+--------------------+---------+------+---------+----------+---------+
| Collation | Charset | Id | Default | Compiled | Sortlen |
+--------------------+---------+------+---------+----------+---------+
| ascii_bin | ascii | 65 | Yes | Yes | 1 |
| binary | binary | 63 | Yes | Yes | 1 |
| gbk_bin | gbk | 87 | | Yes | 1 |
| gbk_chinese_ci | gbk | 28 | Yes | Yes | 1 |
| latin1_bin | latin1 | 47 | Yes | Yes | 1 |
| utf8_bin | utf8 | 83 | Yes | Yes | 1 |
| utf8_general_ci | utf8 | 33 | | Yes | 1 |
| utf8_unicode_ci | utf8 | 192 | | Yes | 1 |
| utf8mb4_bin | utf8mb4 | 46 | Yes | Yes | 1 |
| utf8mb4_general_ci | utf8mb4 | 45 | | Yes | 1 |
| utf8mb4_unicode_ci | utf8mb4 | 224 | | Yes | 1 |
+--------------------+---------+------+---------+----------+---------+
11 rows in set (0.00 sec)
e.g:
CREATE DATABASE universe DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_bin;字符集 (character set) 是符号与编码的集合。
TiDB 中的默认字符集是 utf8mb4,与 MySQL 8.0 及更高版本中的默认字符集匹配。
排序规则 (collation) 是在字符集中比较字符以及字符排序顺序的规则。
COLLATE 子句
tidb> select * from test.c1 order by name;
+------+
| name |
+------+
| A |
| B |
| C |
| a |
| b |
| c |
+------+
tidb> select * from test.c1 order by name collate utf8mb4_unicode_ci;
+------+
| name |
+------+
| A |
| a |
| B |
| b |
| C |
| c |
+------+
以下示例取自官方文档:
https://docs.pingcap.com/zh/tidb/v6.0/character-set-and-collation:
观察在排序规则为 utf8mb4_bin 和 utf8mb4_general_ci 情况下两个不同的结果:
tidb> SET NAMES utf8mb4 COLLATE utf8mb4_bin;
tidb> SELECT 'A' = 'a';
+-----------+
| 'A' = 'a' |
+-----------+
| 0 |
+-----------+
tidb> SET NAMES utf8mb4 COLLATE utf8mb4_general_ci;
tidb> SELECT 'A' = 'a';
+-----------+
| 'A' = 'a' |
+-----------+
| 1 |
+-----------+