1 TiDB 整体架构
TiDB 集群主要包括三个核心组件:TiDB Server,PD Server 和 TiKV Server。此外,还有用于解决用户复杂 OLAP 需求的 TiSpark 组件和简化云上部署管理的 TiDB Operator 组件。
架构图解
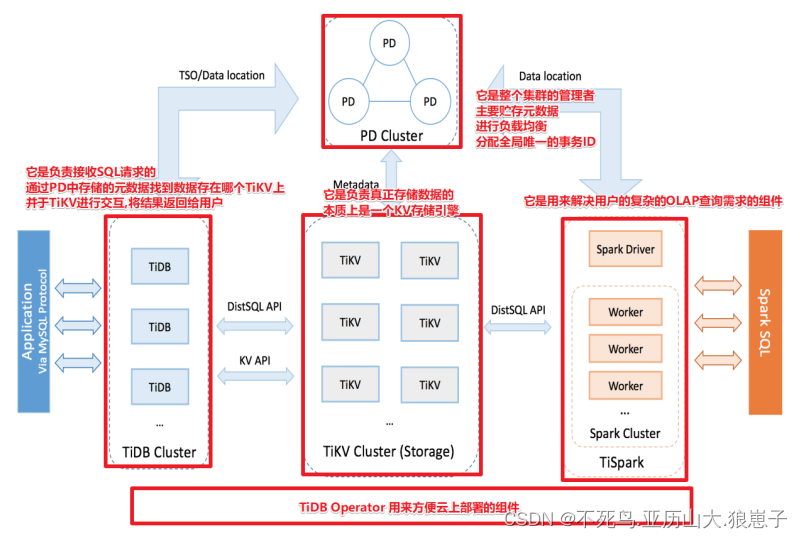
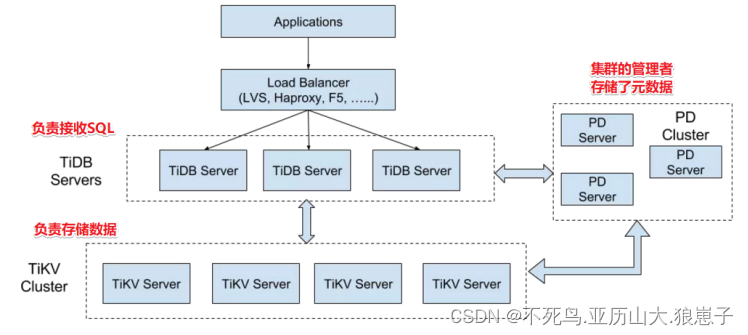
1.1 TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。
1.2 PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个:一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。
PD 通过 Raft 协议保证数据的安全性。Raft 的 leader server 负责处理所有操作,其余的 PD server 仅用于保证高可用。建议部署奇数个 PD 节点。
1.3 TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
1.4 TiSpark
TiSpark 作为 TiDB 中解决用户复杂 OLAP 需求的主要组件,将 Spark SQL 直接运行在 TiDB 存储层上,同时融合 TiKV 分布式集群的优势,并融入大数据社区生态。至此,TiDB 可以通过一套系统,同时支持 OLTP 与 OLAP,免除用户数据同步的烦恼。
1.5 TiDB Operator
TiDB Operator 提供在主流云基础设施(Kubernetes)上部署管理 TiDB 集群的能力。它结合云原生社区的容器编排最佳实践与 TiDB 的专业运维知识,集成一键部署、多集群混部、自动运维、故障自愈等能力,极大地降低了用户使用和管理 TiDB 的门槛与成本。
2 TiDB 核心特性
TiDB 具备如下众多特性,其中两大核心特性为:水平扩展与高可用
(1)高度兼容 MySQL
大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移。
对于用户使用的时候,可以透明地从MySQL切换到TiDB 中,只是“新MySQL”的后端是存储“无限的”,不再受制于Local的磁盘容量。在运维使用时也可以将TiDB当做一个从库挂到MySQL主从架构中。
(2)分布式事务
TiDB 100% 支持标准的 ACID 事务。
(3)一站式 HTAP 解决方案
HTAP: Hybrid Transactional/Analytical Processing
TiDB 作为典型的 OLTP 行存数据库,同时兼具强大的 OLAP 性能,配合 TiSpark,可提供一站式 HTAP 解决方案,一份存储同时处理 OLTP & OLAP,无需传统繁琐的 ETL 过程。
(4)云原生 SQL 数据库
TiDB 是为云而设计的数据库,支持公有云、私有云和混合云,配合 TiDB Operator 项目 可实现自动化运维,使部署、配置和维护变得十分简单。
(5)水平弹性扩展
通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
(6)真正金融级高可用
相比于传统主从 (M-S) 复制方案,基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动恢复 (auto-failover),无需人工介入。
2.1 水平扩展
无限水平扩展是 TiDB 的一大特点,这里说的水平扩展包括两方面:计算能力(TiDB)和存储能力(TiKV)。
TiDB Server 负责处理 SQL 请求,随着业务的增长,可以简单的添加 TiDB Server 节点,提高整体的处理能力,提供更高的吞吐。
TiKV 负责存储数据,随着数据量的增长,可以部署更多的 TiKV Server 节点解决数据 Scale 的问题。
PD 会在 TiKV 节点之间以 Region 为单位做调度,将部分数据迁移到新加的节点上。
所以在业务的早期,可以只部署少量的服务实例(推荐至少部署 3 个 TiKV, 3 个 PD,2 个 TiDB),随着业务量的增长,按照需求添加 TiKV 或者 TiDB 实例。
2.2 高可用
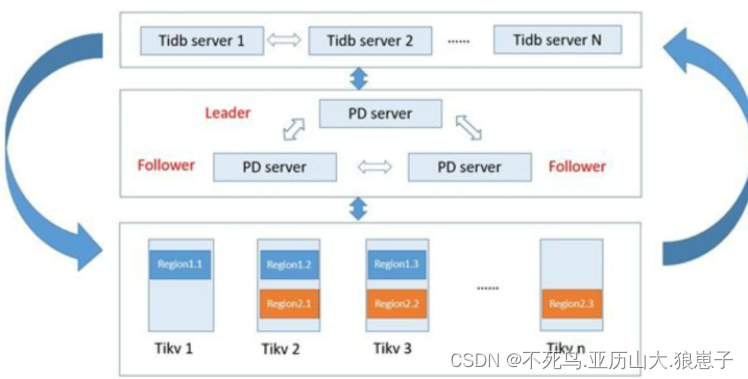
高可用是 TiDB 的另一大特点,TiDB/TiKV/PD 这三个组件都能容忍部分实例失效,不影响整个集群的可用性。下面分别说明这三个组件的可用性、单个实例失效后的后果以及如何恢复。
(1)TiDB
TiDB 是无状态的,推荐至少部署两个实例,前端通过负载均衡组件对外提供服务。当单个实例失效时,会影响正在这个实例上进行的 Session,从应用的角度看,会出现单次请求失败的情况,重新连接后即可继续获得服务。单个实例失效后,可以重启这个实例或者部署一个新的实例。
(2)PD
PD 是一个集群,通过 Raft 协议保持数据的一致性,单个实例失效时,如果这个实例不是 Raft 的 leader,那么服务完全不受影响;如果这个实例是 Raft 的 leader,会重新选出新的 Raft leader,自动恢复服务。PD 在选举的过程中无法对外提供服务,这个时间大约是3秒钟。推荐至少部署三个 PD 实例,单个实例失效后,重启这个实例或者添加新的实例。
(3)TiKV
TiKV 是一个集群,通过 Raft 协议保持数据的一致性(副本数量可配置,默认保存三副本),并通过 PD 做负载均衡调度。单个节点失效时,会影响这个节点上存储的所有 Region。对于 Region 中的 Leader 节点,会中断服务,等待重新选举;对于 Region 中的 Follower 节点,不会影响服务。当某个 TiKV 节点失效,并且在一段时间内(默认 30 分钟)无法恢复,PD 会将其上的数据迁移到其他的 TiKV 节点上。
3 TiDB 存储和计算能力
3.1 存储能力-TiKV-LSM
TiKV Server通常是3+的,TiDB每份数据缺省为3副本,这一点与HDFS有些相似,但是通过Raft协议进行数据复制,TiKV Server上的数据的是以Region为单位进行,由PD Server集群进行统一调度,类似HBASE的Region调度。
TiKV集群存储的数据格式是KV的,在TiDB中,并不是将数据直接存储在 HDD/SSD中,而是通过RocksDB实现了TB级别的本地化存储方案,着重提的一点是:RocksDB和HBASE一样,都是通过 LSM树作为存储方案,避免了B+树叶子节点膨胀带来的大量随机读写。从何提升了整体的吞吐量。
3.2 计算能力-TiDB Server
TiDB Server本身是无状态的,意味着当计算能力成为瓶颈的时候,可以直接扩容机器,对用户是透明的。理论上TiDB Server的数量并没有上限限制。
4 总结
TiDB作为新一代的NewSQL数据库,在数据库领域已经逐渐站稳脚跟,结合了Etcd/MySQL/HDFS/HBase/Spark等技术的突出特点,随着TiDB的大面积推广,会逐渐弱化 OLTP/OLAP的界限,并简化目前冗杂的ETL流程,引起新一轮的技术浪潮。
一言以蔽之,TiDB,前景可待,未来可期。


